Palindrome
A palindrome is a word or phrase that is spelled the exact same when reading it forwards or backward. Palindromes are allowed to be lowercase or uppercase, contain spaces, punctuation, and word dividers.
Algorithms that check for palindromes are a common programming interview question.
The word “racecar” is a valid palindrome, as it is a word spelled the same when read backwards and forwards. The examples below show valid cases of checking the palindrome “racecar”:
| |
racecar -> r == r
| |
racecar -> a == a
| |
racecar -> c == c
|
racecar -> left index == right index -> return trueTo check for palindromes, a string’s characters are compared starting from the beginning and end then moving inward toward the middle of the string while maintaining the same distance apart. In this implementation of a palindrome algorithm, recursion is used to check each of the characters on the left-hand side and right-hand side moving inward.
func isPalindrome(_ str: String) -> Bool {
let strippedString = str.replacingOccurrences(of: "\\W", with: "", options: .regularExpression, range: nil)
let length = strippedString.count
if length > 1 {
return palindrome(strippedString.lowercased(), left: 0, right: length - 1)
}
return false
}
private func palindrome(_ str: String, left: Int, right: Int) -> Bool {
if left >= right {
return true
}
let lhs = str[str.index(str.startIndex, offsetBy: left)]
let rhs = str[str.index(str.startIndex, offsetBy: right)]
if lhs != rhs {
return false
}
return palindrome(str, left: left + 1, right: right - 1)
}Manacher’s Algorithm
Manacher’s algorithm is an algorithm for finding the longest palindromic substring in a string, with a time complexity of O(n) (where n is the length of the string).
The algorithm takes the string S as input and returns:
- An integer array A having the same length as the string S, where the element A[i] represents the length of the longest palindrome radius at position i (i.e., S[(i−A[i])⋯(i+A[i])] is a palindrome and S[(i−A[i]−1)⋯(i+A[i]+1)] is not a palindrome).
For example, for the input S = ‘banana’, the result of A is:

The algorithm is as follows:
- i proceeds from 0 to n-1 (n = |S|)
- R = max(j + A[j]) for all j with j < i, Let j be p. (R = p + A[p])
- The initial value of A[i] is determined depending on whether or not i ≤ R
- If i > R, the initial value of A[i] is zero
- If i ≤ R, then i is within a palindrome centered on p. At this time, we obtain the symmetric point i’ of i around p. The initial value of A[i] is min(R-i, A[i’])
- From the initial value of A[i], A[i] is incremented until S[i-A[i]] and S[i+A[i]] are equal
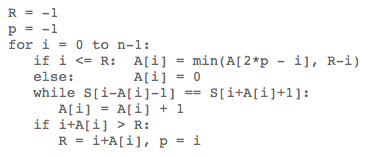
Trie
A trie is an ordered tree data structure used to store dynamic sets or associative arrays with strings. Unlike a binary search tree, nodes in a trie do not store keys associated with that node. Instead, the position in the tree represents the current key. Every descendant of a particular node has the same prefix as that node, and the root node represents an empty string. Values do not exist in all nodes, but only at leaf nodes or inner nodes corresponding to specific keys. To optimize space usage, a compact prefix tree (radix tree) can be used. The word “trie” comes from the word “reTRIEval”. Edward Fredkin, who coined this term, pronounces it the same as “tree”, but others pronounce it as “try”.

Why should I use TRIE?
Tries are useful for quickly and efficiently searching large amounts of text information. A trie is a data structure that can effectively handle dictionary lookups or Internet autocompletion. As mentioned earlier, the name TRIE came from TREE RETRIEVAL. The most typical characteristic is that keyword information exists only at the leaf nodes; the intermediate nodes contain no information except links to child nodes.
Suffix Tree
A suffix tree is a trie-shaped data structure that represents all suffixes of a string. While a trie is called a prefix tree, the key difference is that for a word like “banana”, a trie stores only the word “banana”, but a suffix tree stores all possible suffixes: “banana”, “anana”, “nana”, “ana”, “na”, and “a”.
The reason for storing all these cases is to enable efficient substring searching. With a regular trie data structure, you can find the complete word “banana” or prefixes like “ban” or “ba”, but you cannot find “banana” using substrings like “nan” or “ana”. The suffix tree solves this problem by improving upon the trie structure.
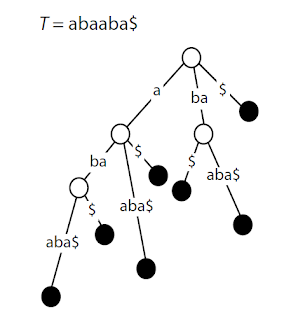
Since edges can have string labels, a distinction must be made between two meanings of ‘depth’:
- Node depth: The number of edges that must be traversed from the root to reach the node
- Label depth: The total length of all edge labels along the path from the root to the node



